
My agents get the models they need
You don’t fight a houseplant with a fire hose. So why run every job on a frontier model?

The picture is a joke with a point. A fireman, both hands on the hose, blasting a gardener square in the face. The gardener, soaked, calmly hosing the woman beside him. The woman tipping a watering can onto a single seedling. Same plant. Wildly different force. Nobody flinches.
That is most AI setups right now. One enormous model, pointed at everything. Sort a list — frontier model. Tag an email — frontier model. Draft a reply that’s three words long — frontier model. It works. It’s also daft: slow where it needn’t be, dear where it needn’t be, and welded to one supplier who knows it.
So we don’t do that. Articulate runs a fleet — and, more to the point, a layer on top that decides which boat to put each job in.
The 10 p.m. drive to Abu Dhabi
One floor of that fleet I couldn’t rent. I wanted a model running on a machine in my own room — nothing leaving the building, nothing metered, the cheap and private floor of the stack. For that you need the hardware. A Mac Studio.
Dubai was out of them. So was every reseller I rang. The last one Apple had anywhere in the country was sitting in a stockroom in Abu Dhabi — a single unit, ninety minutes down the E11. So at ten o’clock at night I got in the car and drove to Abu Dhabi to buy the last Mac Studio available from Apple in the country.
It sits in the corner of a room in Dubai now, quietly running the local models — the on-box floor of the fleet. $0 a call. Data that never leaves the room. The kind of thing a bank or an insurer in this region doesn’t file under “feature” — it’s the whole reason they’ll take the meeting.
Which is what let me build this:
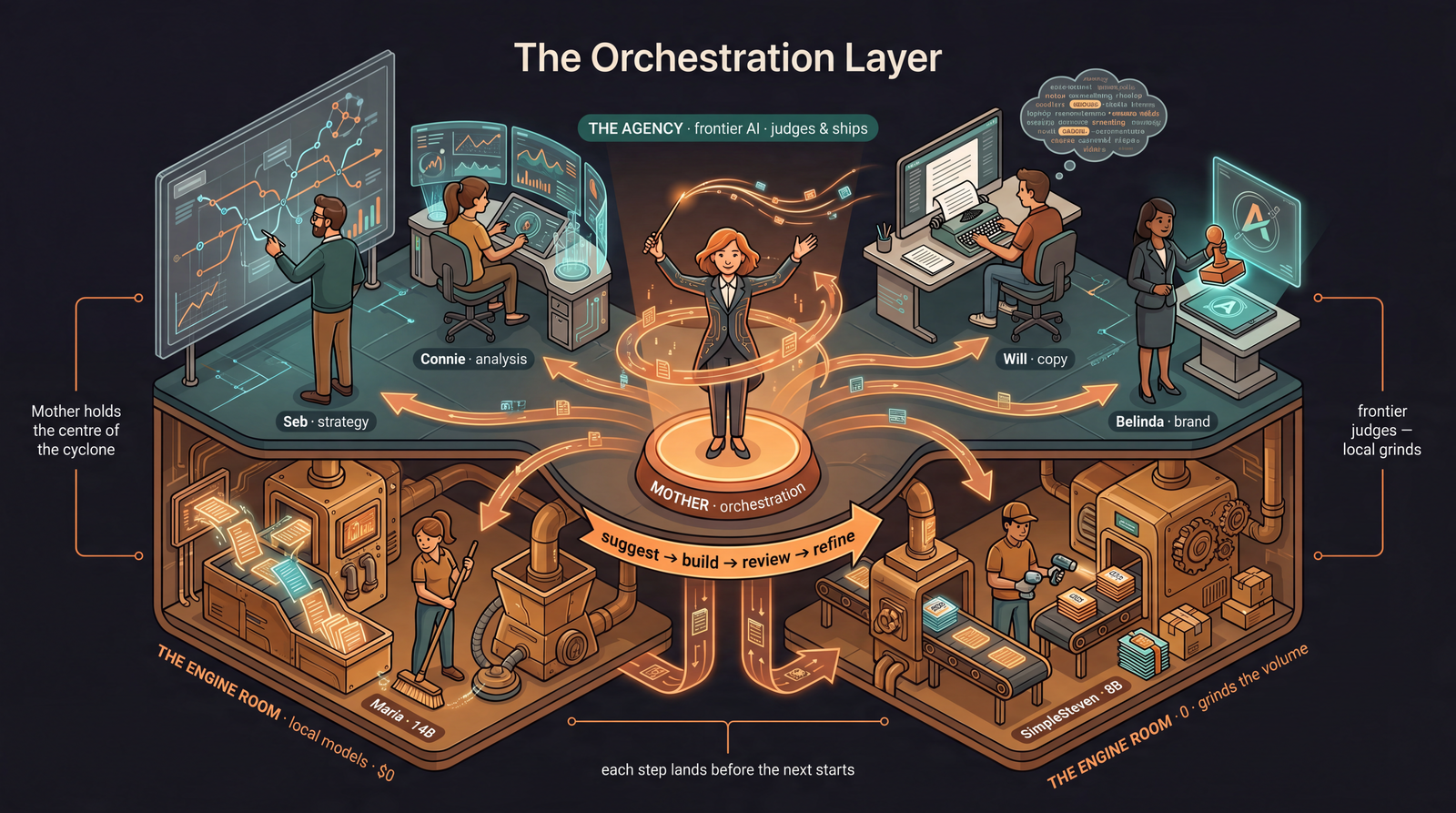
Two floors, one conductor. Upstairs, the Agency — the frontier models, the expensive ones with judgement, the work that ships and faces the client. Downstairs, the Engine Room — the small local models on that Abu Dhabi machine, free to run and private by default, doing the dull, repeatable sixty percent. You don’t send the partner to alphabetise the filing.
What we run
Why we do it
Because the job should pick the tool, not the other way round. A frontier model on a sorting task is a fireman watering a window box — impressive, expensive, and missing the point. Right-sizing isn’t penny-pinching. It’s craft. The cheap model frees the budget for the moment that genuinely needs the heavy one.
And running a fleet, not a favourite, keeps us honest. The models leapfrog each other every few months. Weld your whole operation to one of them and you inherit its bad weeks and its price rises. I’d rather keep the door open.
What’s in it for you
Five plain things, no jargon:
You pay for the work, not the wattage. Cheap tasks run on cheap models, and the saving is real and yours. It’s quicker — light jobs don’t queue behind a heavyweight that needn’t be there. You’re not married to one vendor — a better or cheaper model lands, we route to it, and you feel the upgrade, not the migration. Your data can stay where the law wants it — regional or fully on-box inference for PDPL-strict work, no detour through someone else’s jurisdiction unless you choose it. And you own it at the end — the stack hands over to your accounts; no retainer holding your keys hostage.
Quality where it counts. Economy where it doesn’t. And an agent on top that knows the difference — so you never have to think about it.
That’s the whole idea. My agents get the models they need. Not the biggest one in the shed.
Curious what your stack should actually be running?
That’s the conversation. I sit with one person or couple a day, look at where the work really is, and map which jobs want a heavyweight and which want a workhorse. No deck. Forty-five minutes, no charge for the first one.
Talk to Anthony →